Bath University Deep Racer Cup
Posted by: Constantinos Liagas
Some basic Machine Learning in practice with Amazon Web Services DeepRacer.
Back in September, among the flurry of emails and notifications for new activities being launched, I received a very interesting invitation from the ART-AI CDT, to the Amazon Web Services DeepRacer student competition. You can find a link to the main website here, but Amazon also runs the student version which is free to enter. It is a simplified version, but remarkable in how well it is designed and delivered, allowing attendees (even those with little to no previous experience of machine learning) to be up and running quickly and easily.
CDTs in Bath tend to organise their own activities according to specific interests, but invites always go out across campus to invite fellow PhD students from outside, interested in joining. Back In September, the ART-AI CDT sent out the call to both us (AAPS CDT) and the SAMBa CDT, so along with Yuqiang and Indrek we joined. Thoughout the year, we get the chance to be involved in a number of activities around various interests and this was personally, my first foray into practical Machine Learning (at least in a very well organised and simplified manner). However, Indrek is already involved with a number of our other colleagues from the CDT in Formula 1TENTH and has had experience building and programming the AAPS CDT buggy, which we hope will be able to join competitively this year.
The week before the competition we were given an online tutorial on how to use the DeepRacer web interface to train our Machine Learning model to drive the buggy in a simulated environment. On the day of the competition, we would be tranferring our model onto the buggy and unleashing it into the real world on a track to see how it could cope outside the sterile simulation environment.
Essentially the task we were given prior to competition day, was to write a reward function for the agent to train with, using Reinforcement Learning (RL). RL, is a subset of Machine Learning (ML) that tasks the agent with exploring a state space and maximising the reward it receives for navigating through this space. In simple English, we were to write a piece of code that would give out a number. This number was the result of logic and calculations occurring within that piece of code and those calculations took into account various parameters the buggy is able to determine from its environment, like how far away it is from the centre of the road, how fast it is travelling or how many degrees of steering angle it is using. A full list of available parameters we could use, can be found on the AWS DeepRacer Website here. The student version of DeepRacer gives students ten hours of "compute time" to use per month, to train their models and we were told to aim to consume eight of those hours by the day of the competition, leaving the last two hours for on-the-day refinements.
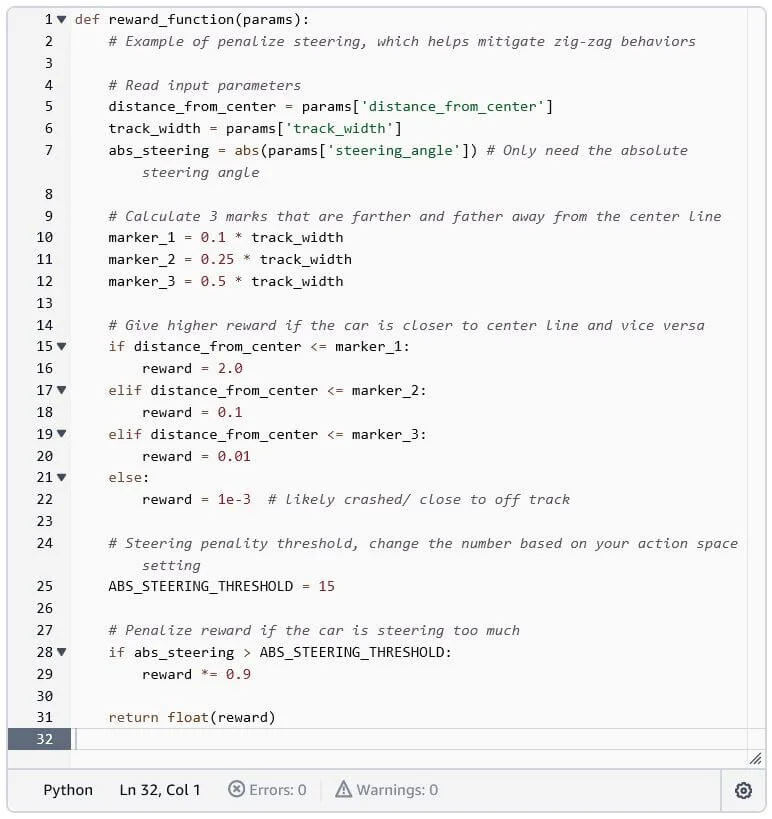
Promptly enough, we went about designing our reward functions and set about training our models. The simulated environment allowed us to take trial runs at the course with our trained models, meaning that we were able to make changes to our reward functions and see the effect on the buggy, fairly quickly within the virtual environment (like the one in the figure on the left). Although only a fun, learning game in this instance, the automotive industry is investing vast sums of money to develop systems like this for its own purposes that allow for virtual validation of new vehicles, reducing the cost of development by not requiring expensive prototypes to be physically built and allowing for extreme case validation, far easier than in real life testing. Simply change the environment in the simulation and test your system under the new conditions.
On the day, the competition was held at the American Museum. Arriving at about 09:30 in the morning, the rain was torrential so we quickly dived for cover into the main room, but by lunchtime it was easing off and during a brief pause in the rain, we went for a walk around the grounds to get some fresh air and admire the gardens. (Indrek and Yuqiang on the right, enjoying a rest at the bust of Winston Churchill) It is a very nice place to visit in Bath as you can see from the pictures below and only a few minutes’ walk from campus.


Before we arrived, the AWS Team were hard at work setting up the arena so that everything was ready for the competition.

By 10:00am, the track was all set up and we all got down to preparing model files for transfer to the buggy. After a number of iterations, (8 in my case) we were ready to compete!


The competition was open to all attendees either individually or as a team and everyone got a chance to run two of their models around the track until lunchtime. From there, the top three fastest models would be pitted against each other in a final heat, to see whose model was the quickest around the track.
It was very interesting to see the effects of reality on the model behaviour. Everything was slightly off from the simulation, from the width of the track, the bumps in the mat surface, visible lines where the mats joined, shadows cast by the Amazon team member following the car from behind in case it went off track, to the existence of an AWS logo in the “grass” area which was not in the virtual environment. Everything had an effect but one thing that struck me was the unrecoverable state of having lost sight of the yellow centre line. Once the front-facing camera on the buggy had lost sight of this, for almost all competitors, including my own model, the buggy careered off into a wall either directly or with its wheels stuck at some steering angle.
As an engineer, I am much more interested in how things break rather than how they work. It is often much more valuable an observation. This was an interesting learning moment for me as my mind is primed from experience in procedural programming where my code has access to memory and am able to iterate through a piece of code. I immediately chose to try to introduce something like this in my reward function, having misunderstood what is happening on the buggy during a real run. After discussing this possibility with the Amazon Team Lead, his confused reaction gave the game away pretty quickly. My question was based on incorrect assumptions about the system and was in fact, invalid.
I still had two hours of compute time left though, to try and train my model to behave better in the real world, so armed with a better understanding of the system and new knowledge of its environment, I tweaked my code for the final training session and crossed my fingers for the best. Yuqiang and Indrek were also on the look out for potential last-minute tweaks but it became evident (counterintuitively) that simpler reward functions with a small amount of training, were outperforming longer-trained models or ones with more complex reward functions.
By about 15:00 and with the smallest of margins keeping me in the top three, I was given the chance to run my last model for a final trial against the two fastest models. Jokingly and somewhat nervous, we all questioned each other if we would be using an updated model for the final run. Sure enough, all three of us would be pitching our latest and greatest in a final 2min free run. Unlimited laps, but the clock stops at 2 minutes, with the fastest lap marked as the final result for each competitor.
As explained above, to little surprise by this time, all three of our models actually performed worse than our first tries but we all kept the same ranking.
All in all, a great day with lots of fun with fellow students and many interesting conversations about AI/ML/RL and their practical implications.
